This article was first published on November 13, 2016 on my linkedin page: https://www.linkedin.com/pulse/were-polls-wrong-we-how-trumps-win-way-within-whims-gyasi-dapaa/
Last Tuesday’s (Nov 8, 2016) elections coverage was one of the most exhilarating to watch on TV. This was surprising because almost all the news networks and their respective viewers(even including Trump supporters) had been conditioned to expect an easy night for Hillary Clinton. In fact, the only person who thought Trump could win was Trump himself. But I am sure, even he, had serious doubts given all the voices, both internal and external, that told him he could not win. The expectations that had been set were so lopsided that I wouldn’t be surprised if Hillary only prepared a victory speech and Trump, a concession one. No wonder when the opposite outcome actually happened, Trump’s victory speech felt extemporaneous or rashly prepared at best, and Hillary had to give her concession on the following day. The words of the political news commentators, as their expectations crumbled, were also part of the fun. Jake Tapper, the chief Washington Correspondent for CNN, asked with stark disappointment and hopelessness, whether the pollsters, having utterly mispredicted the election results, had a future in the business of using data to project election outcomes? As a data scientist and someone who believes palpably in the future of data, I share the collective burden to defend and protect the value of data, which is profuse if handled(prepared, analyzed and interpreted) appropriately. Hopefully, this article will help us understand polls data better and appreciate its potency more.
Was Trump’s Win Really Surprising?
Within seven days of the elections, most polls including that of the world renowned pollster, Nate Silver, had Clinton winning with a 70% probability. While this is by any measure a sizable winning odds, it’s by no means a guaranteed outcome as it’s mistaken for by most people. Trump’s winning probability of 30%, even though smaller than Clinton’s, was not improbable either. In fact, it was a fairer chance than most people imagined. And so Trump’s win should never have caught us by surprise. If a million bucks was hidden in one of three boxes, and I guessed that golden box, would that be surprising? Not Really. In fact, most statisticians –experts on risks and chances—would consider something as strange or surprising if it had less than 5% chance of happening. And Trump’s chances were estimated to be over 600% higher than this threshold. We will therefore have to adjust our characterization of surprise or will have to brace ourselves for more surprises, as we have experienced in recent months with Brexit and Trump’s victory. This is because things that happen with a 30% (or even 10%) probability happen more often than we think.
The noble prize laureate and renowned psychologist, Daniel Khaneman, explains in his book, ‘Thinking Fast and Slow’, how we as human beings struggle to think probabilistically except for 0 or 1 probabilities. Perhaps, it’s because of this probability difficulty that makes us rather award all the winning chips to the contestant with higher probability, and fully expect her to win.
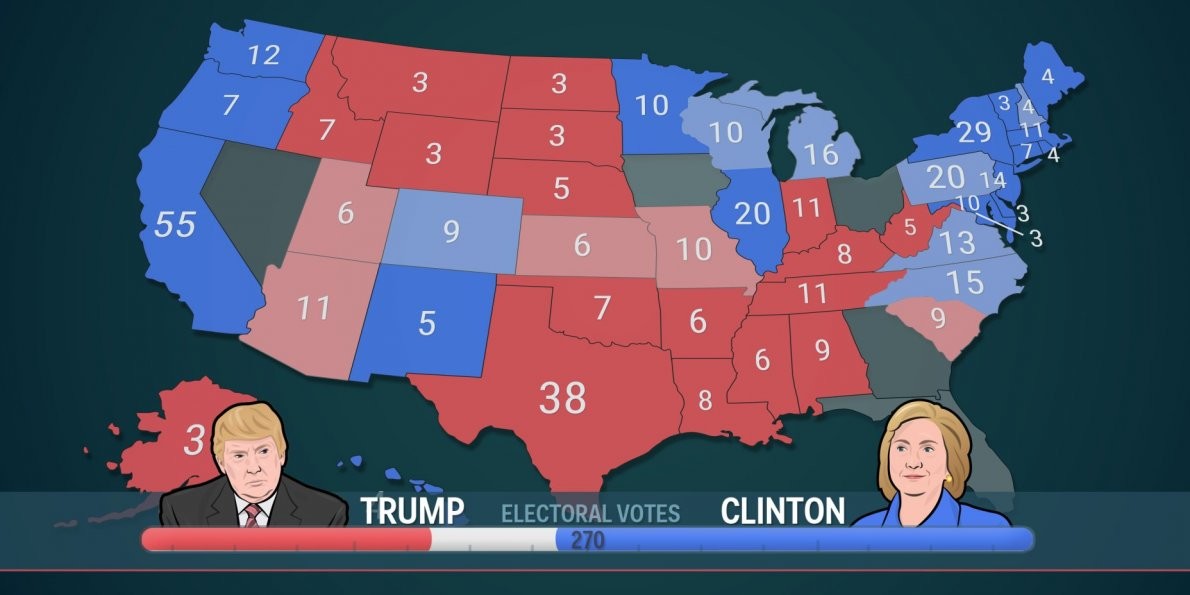
Does a 4% advantage in Polls Guarantee a Win? The Polls May Not Have Missed the Crack in the Blue Firewall Neither
One of the arguments that made us all believe in a cinched Clinton success was the idea of an insurmountable defense Clinton had mounted via what was called the Blue Firewall (which comprised of states like Wisconsin, Michigan, Pennsylvania, Virginia and Maryland). I always wondered why they called it a firewall especially when the advantage she held in most of the polls of these states was only around 4%; with margins of poll error typically around 3%, a 4% winning advantage may look significant on the surface and in nominal terms, but a wash in statistical currency. This neglect of margin of error or failure to accurately account for it is not only exclusive to the analysis of election polls, but also prevalent in business. It’s not uncommon for a chief economist of a company to forecast a 240M revenue with a 30M margin of error; only to be berated with votes of chagrin and no confidence from the executives when actual revenue turn out to be, say, 200M, a value way within the 95% confidence range of (180M, 300M).
With a 3% margin of error, you need at least a 6% (twice as much as the margin of error) advantage in polls for an almost sure victory; and also, given the fact that this election was prone to a Bradley(Social Desirability) Effect Bias, a 6% winning cushion may even be deficient and not enough to guarantee an almost sure win. It was therefore astonishing to watch CNN’s seasoned election analyst, Don King, click these otherwise competitive states freely into Clinton’s bucket, giving her a formidable projected advantage of more than 80 electoral votes over her rival. Such a cursory distribution of electoral votes is bound to result in large prediction errors in electoral votes, and potentially, a miscall of the presidency. This begs the question of whether there is a better way to assign electoral votes based on the polls. And the answer is straightforward. Yes.
Probability-Weighted Electoral Map Would Ensure the Least Prediction Errors
Because electoral votes are assigned via a winner-take-all system after the fact doesn’t mean they have to be distributed as such before the fact. In other words, Don King doesn’t have to assign all 10 votes of Wisconsin to Clinton because of her 4% lead in the polls. Since outcomes are only known with sure certainty after the fact but probabilistically before the fact, we will increase our accuracy by multiple fold if we assign the votes of an electoral college based on the probabilities of win. For instance, a 4% poll advantage is roughly a 75% chance of winning the states (assuming a 3% margin of error); hence, if that state happens to be Wisconsin, 7.5 of the 10 electoral votes should go to the leader candidate, and the remaining 2.5 votes to the trailing candidate. When such an approach is implemented for each state and aggregated, the total estimated electoral votes will be much more accurate and closer to actual outcomes than the current methodology of awarding all electoral votes to the candidate leading in the polls.
Other Related Matters: Measuring and Assessing the Efficacy of Pollsters
Apart from working on how we interpret and analyze polls, we ought to also change the way we measure our pollsters. Pollsters are not geniuses when they call an election and dumb asses when they miscall it. We should pay more attention to a pollster’s predicted percentages for the candidates rather than merely grading him on his ability to call the winner. For instance, in the Michigan Democratic Primaries between Clinton and Sanders, the problem should be less about the pollster’s failure to predict a Sanders’ win, and more about their almost unpardonable prediction error of 20% or more in some cases. When we do this, we may be able to determine the subset of pollsters whose numbers should be trusted more especially in times of close elections, where a 1% difference can tilt victory to the opposite direction.
And Finally, Data and Analytics are not Dead
Data is not dead but just getting started with the advent of big data. Anyone who doubts this should just look at the latest business models and acquisitions happening: Uber, Tesla, Walmart acquiring Jet.com, Verizon acquiring Yahoo, and so on and so forth. All of these have big data play. And the reason for this is the inexorable fact that, in today’s complex world, the company that wisely decides with data will perforce outthink and outcompete the company deciding erratically with gut and brute wisdom. However, this compelling and profuse value in data can only be unlocked by the development of teams with the expertise of querying, cleaning, analyzing and interpreting data results correctly.




{kind=link}